|
Ayudh Saxena I am currently pursuing a Master's degree in Machine Learning at Carnegie Mellon University. Currently, I am working with Prof. Pradeep Ravikumar on improving representation learning by using clustering as a 'context' to leverage the instrinsic structure of the data. On the side, I have also been working on understanding and improving the social intelligence of current LLMs under the guidance of Prof. Yonatan Bisk. My primary research interests include representation learning and multimodal machine learning, with a focus on developing robust, generalizable, and semantically rich representations. I am also interested in developing intelligent systems that can do reasoning in social contexts. Recently, I have also developed an interest in the mechanistic interpretability of deep learning models, particularly using Sparse Autoencoders to uncover interpretable features. Previously, I worked at Adobe on the Photoshop Express (PsX) app, where I was a founding member of the Video and Generative AI (GenAI) teams. I contributed to introducing new video editing and generative AI capabilities into the app from scratch. During my undergraduate studies at IIT Kharagpur, I developed vBeats, a framework for converting gestures into bass strokes for Indian Tabla, advised by Prof. Sandip Chakraborty. This work earned the Best Poster Award at COMSNETS 2024. Additionally, during my research internship at Adobe Research Bangalore, I developed Videos2Doc, an ML framework for generating documents from procedural videos, which later received a US patent. |

|
|
vBeats: A Framework for Converting Gestures into
Bass Strokes from Indian Tabla using Smartphones
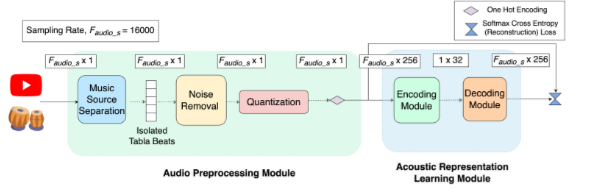
Ayudh Saxena, Soumyajit Chatterjee, Sandip Chakraborty, COMSNETS’24, advised by Prof. Sandip Chakraborty GitHub / IEEE Page vBeats is a novel approach for translating Indian Tabla gestures, captured via smartphone sensors, into corresponding bass strokes. It addresses the challenge of bridging the gap between two modalities with drastically different sampling rates. The system employs a multi-modal framework leveraging autoencoders to learn robust latent representations from inertial and audio signals, followed by LSTMs to map these representations using sequence-to-sequence learning. We also curated a dataset comprising 1.38 hours of synchronized IMU-audio data from professional Tabla players. |
|
Videos2Doc: Generating Documents from a Collection of Procedural Videos
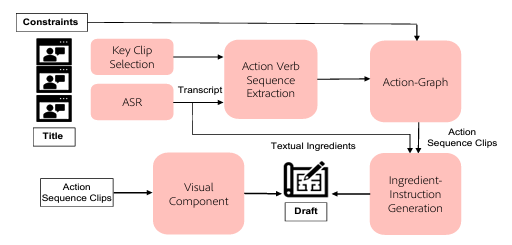
Ayudh Saxena, Tripti Shukla, Aanisha Bhattacharya Jeevana Kruthi Karnuthala, Abhinav Bohra Bhanu Prakash Guda Abilasha Sancheti Niyati Chhaya ACM IUI’22, advised by Dr. Niyati Chhaya ACM Page Videos2Doc is a machine learning framework designed to automatically generate structured documents from collections of procedural videos. The primary challenge involves extracting meaningful information from the diverse multimodal content present in such videos. To accomplish this, we implemented a multi-stage pipeline. First, key video frames are selected by constructing an action graph, which is then input, along with any available textual ingredients, to an encoder-decoder-decoder model to produce coherent instructions. |
Work ExperienceAdobe Inc, Noida - SDE 2 Photoshop Express Team Aug '22 - Aug '24
|
|
Borrowed from Jon Barron website's source code. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. Also, consider using Leonid Keselman's Jekyll fork of this page. |